
Datenanalyse selbstgemacht
Datenanalyse selbstgemacht
Über die Auffindung von Zusammenhängen mit Diagrammen

In meinem letzten Artikel “Impferfolge im Ländervergleich“ kündigte ich an, zu beschreiben, wie jede/r selbst die betreffenden Daten herunterladen und seine eigenen Prüfungen durchführen kann.
So sei es: Viele statistische Dienste, wie z.B. DIVI, RKI, Our World in Data, das britische Office for National Statistics und das amerikanische VAERS erlauben es, die erfassten Daten herunterzuladen und selbst zu analysieren.
Das Vorgehen ist so detailliert beschrieben, dass auch jemand, der noch nie eine Tabellenkalkulation verwendet hat, in die Lage versetzt wird, Auswertungsdiagramme zu erstellen und Zusammenhänge zu untersuchen. Wer im Umgang mit Spread Sheets erfahren ist, braucht nur die Information Daten Herunterladen und ggf. die Abschnitte Beschriftungen und Weitergehende Möglichkeiten.
Our World in Data
Hier beschreibe ich, wie meine Untersuchungen zu den Impferfolgen verschiedener Länder nachvollzogen und geprüft werden können. Die Daten stammen von Our World in Data, das an der Universität Oxford angesiedelt sind, also durchaus als seriöse Datenquelle betrachtet werden sollte: https://ourworldindata.org
Der Dienst bietet seine Daten zum Downlod über Github an.
Daten herunterladen
GitHub ist urprünglich ein netzbasierter Dienst zur Versionsverwaltung für Software-Entwicklungsprojekte, wird aber zunehmend auch für den Austausch wissenschaftlicher Daten genutzt. Nebenbei: “Versionsverwaltung” bedeutet, dass Dateien verwaltet werden und von jeder Datei auch alle vorherigen Versionen verfügbar sind.
Das Basisverzeichnis aller Daten von Our World in Data (ab jetzt nur noch owid) genannt, ist hier: https://github.com/owid, uns interessieren jetzt erst einmal nur die Covid-Daten: Unter der Verzeichnisstruktur https://github.com/owid/covid-19-data findet sich unter anderem die Datei https://github.com/owid/covid-19-data/blob/master/public/data/latest/owid-covid-latest.csv, in der alle paar Stunden automatisch der neueste Stand der Statistiken veröffentlicht wird:
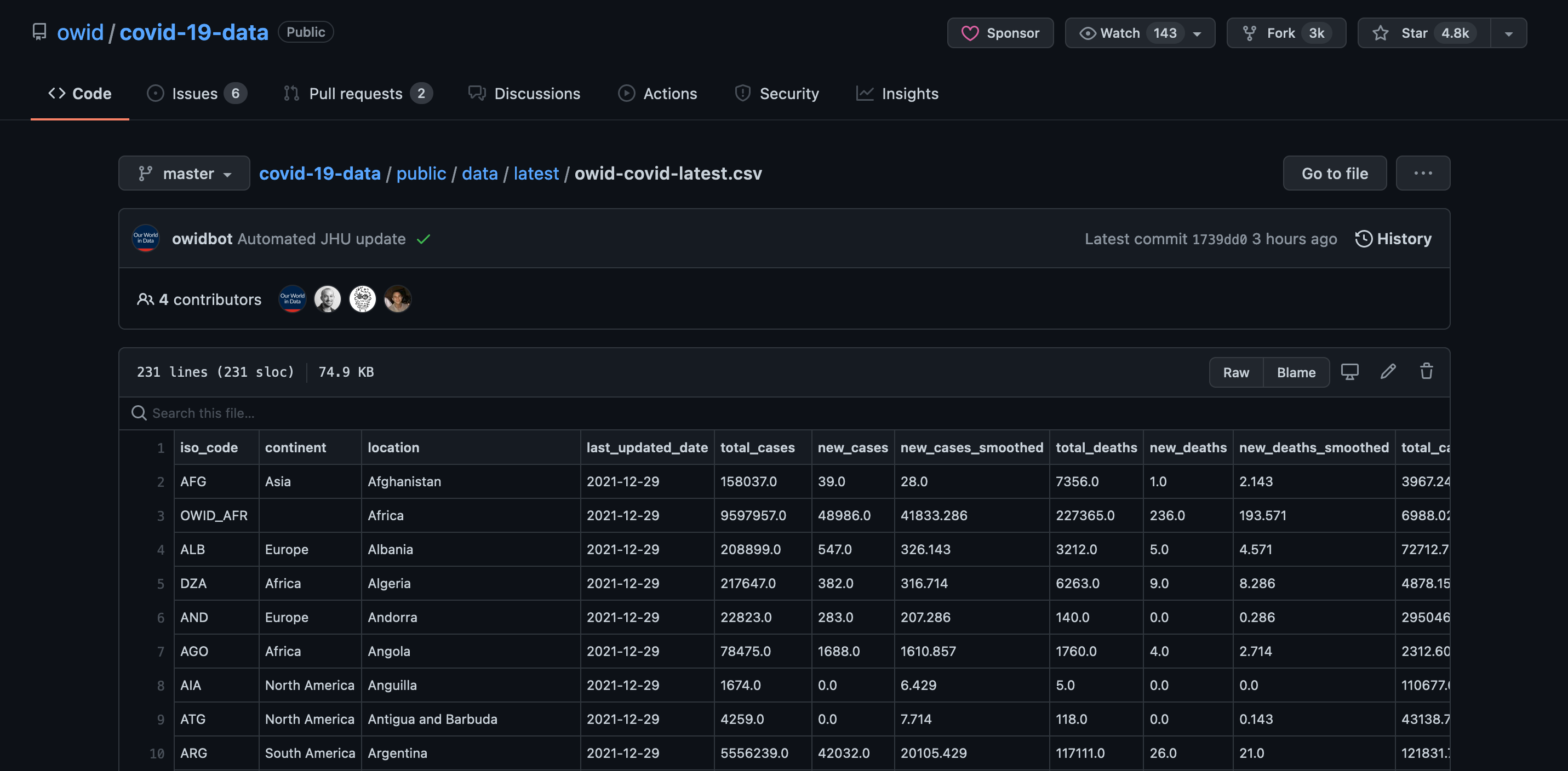
Sie führt aus unterschiedlichen Quellen die Daten für 231 Staaten und Territorien zusammen und kann über den Knopf “raw” als Textdatei im CSV-Format heruntergeladen werden:
CSV ist ein Dateiformat, das eine Tabelle wie oben angezeigt in einfacher Textform enthält, und ungefähr so aussieht:

Damit können wir natürlich noch nicht viel anfangen. Tabellenkalulations-Software hilft uns weiter, z.B. Excel von Microsoft oder OpenOffice von Apache. Letztere ist eine kostenlos und für alle gängigen Betriebssysteme verfügbare Software, daher bescheibe ich das weitere Vorgehen an ihrem Beispiel.
Datenimport in OpenOffice
Heruntergeladen kann die Software über https://www.openoffice.org/de/. Nach der Installation kann man die Datei aus dem Hauptmenü heraus öffnen per Datei – Öffnen:
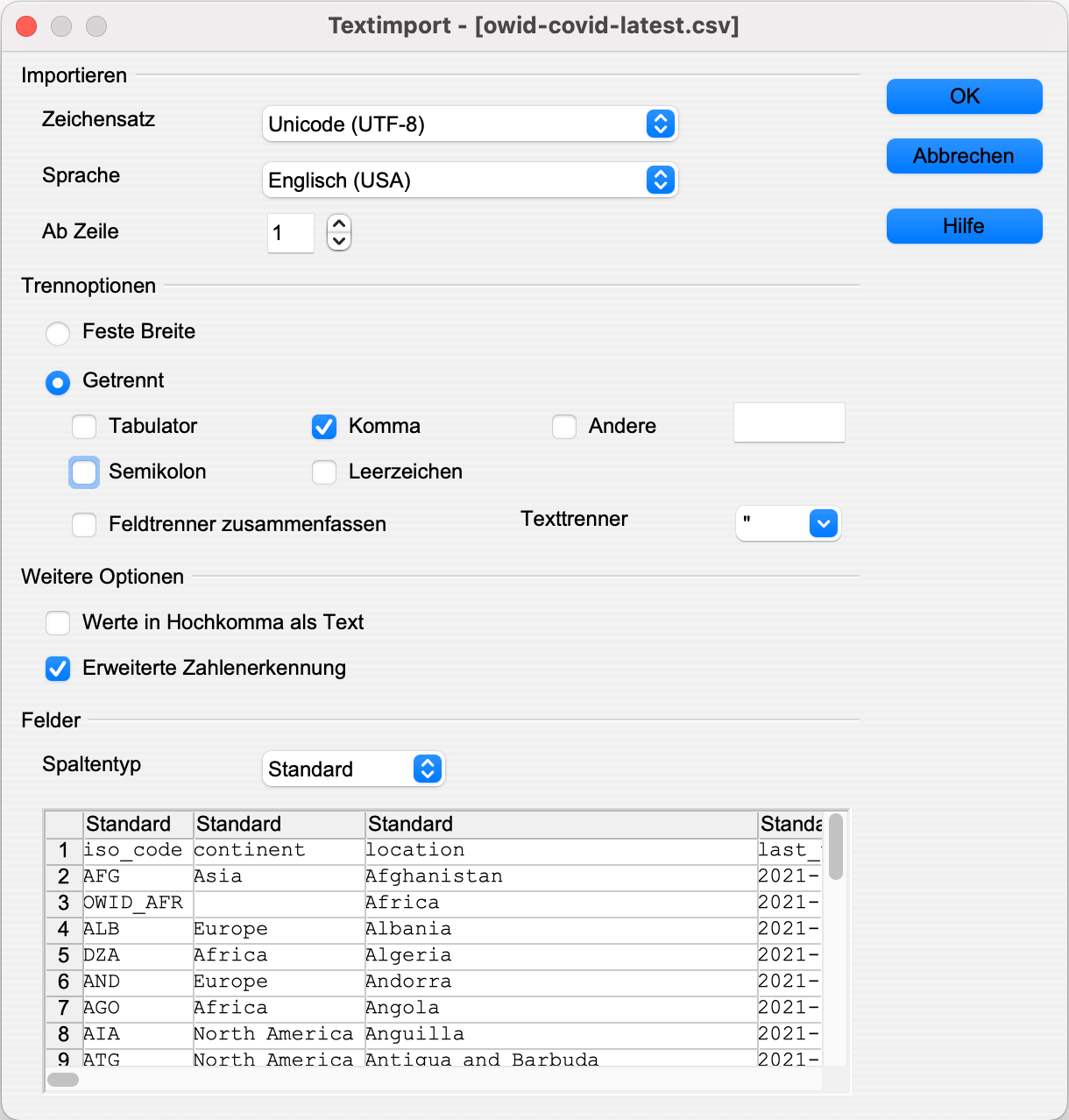
Es erscheint ein Dialog zur Einstellung eventueller Besonderheiten der Datei. Für owid sind folgende Einstellungen nötig:
Sprache: Englisch (USA)
Trennoptionen: Getrennt – Komma
Erweiterte Zahlenerkennung
Nun werden die Daten als Tabelle angezeigt und sind weiter verwertbar:

Datenbearbeitung
Die Tabelle ist sehr groß, und um uns das Leben einfacher zu machen, entfernen wir die Daten, die uns nicht interessieren und sortiern die restlichen Spalten um.
Zum Löschen der Spalten A und B markieren Sie diese, indem Sie mit der Maus auf die Spaltenkennung ‘A’ anklicken, die Maus ziehen sie bis auf ‘B’ und dann loslassen. Damit sind die Spalten iso_code und continent markiert. Per Klick mit der rechten Maustaste wird das Kontexmenü geöffnet, auf dem wir Spalten löschen anklicken.
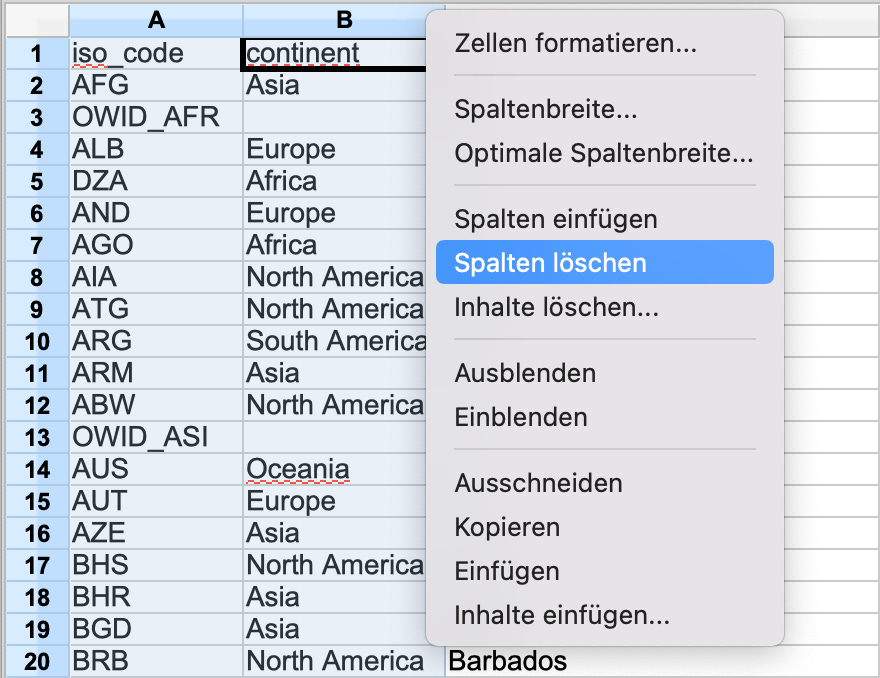
Daraufhin sollten die beiden Spalten entfernt und location in Spalte A sein:
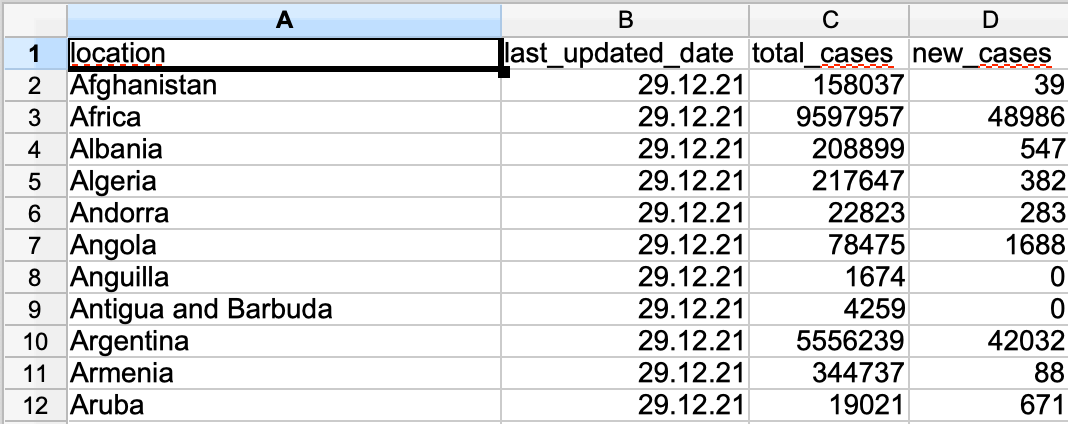
Fügen wir nun zwei leere Spalten ein, indem wir die Spalten B und C markieren (B anklicken und auf C ziehen), rechts klicken und Spalten einfügen wählen.
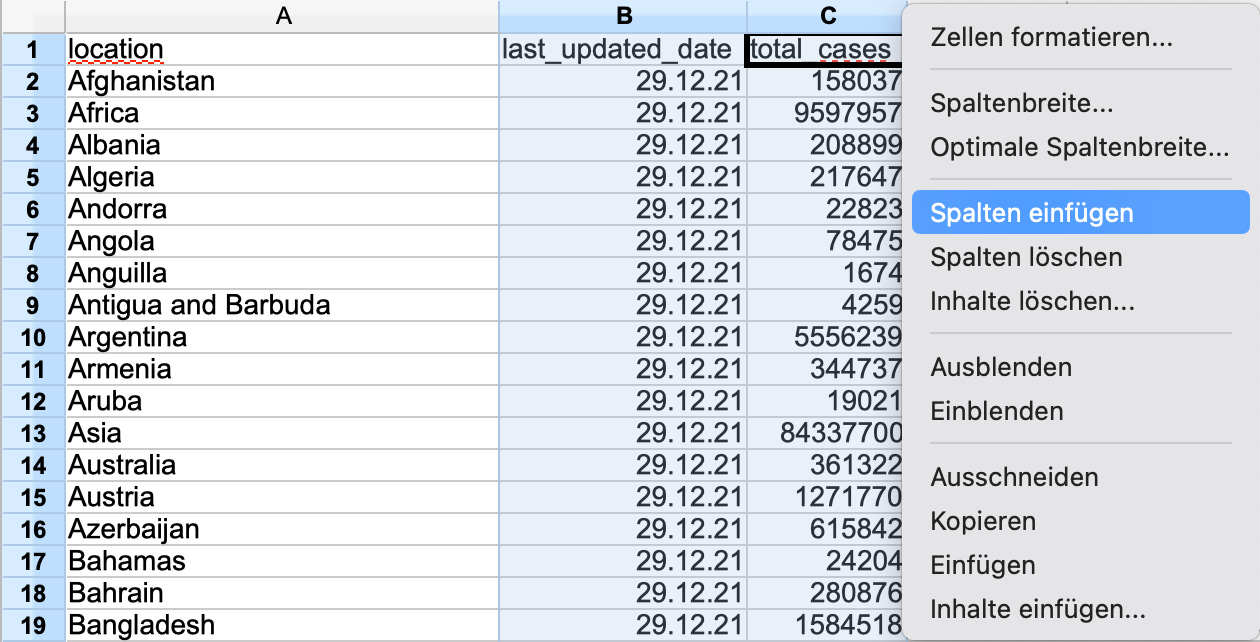
Als Ergebnis finden sich nach der location-Spalte zwei leere Spalten, in die wir die Daten kopieren, die wir vergleichen wollen. Dazu suchen wir zuerst die Spalte mit den Daten für die x-Achse, zum Beispiel people_fully_vaccinated_per_hundred (im Stand Ende 2021 ist das Spalte AQ), markieren Sie durch Klicken auf den Spaltenkopf (AQ), rechtsklicken den markierten Bereich und wählen Kopieren:
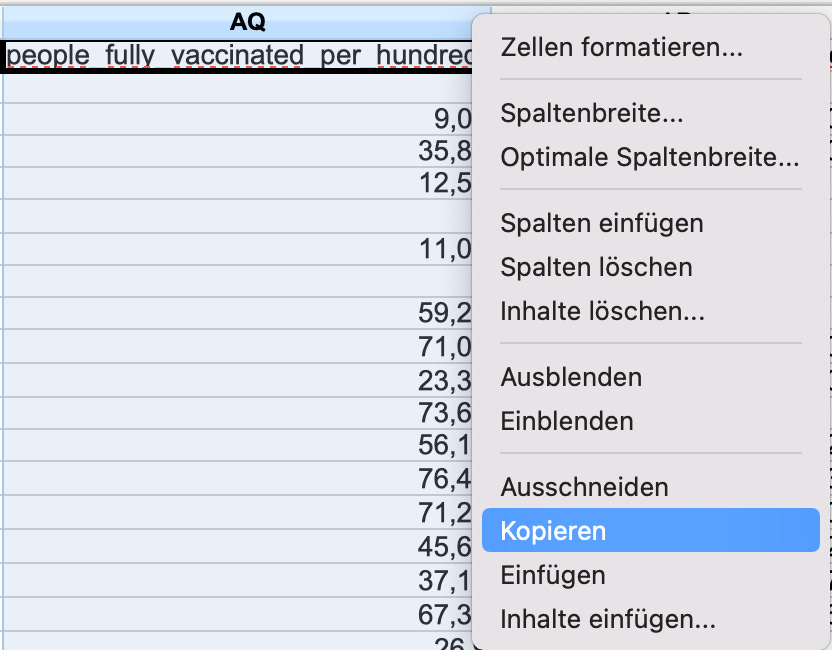
Dann gehen wir zurück auf Spalte B, klicken deren erste leere Zeile mit der rechten Maustaste und wählen Einfügen:
Das gleiche wiederholen wir mit der Spalte reproduction_rate (Aktuell Spalte Q) und fügen Sie in Spalte C ein. Das Ergebnis sollte ungefähr so aussehen:

Diagrammerstellung
Um Diagramme zu erstellen, wählen wir Datenbereiche aus und Diagrammoptionen. Zunächst einmal müssen die Daten noch weiter bereinigt werden. Die Diagrammdarstellung macht Fehler, wenn in der ersten Datenzeile Daten fehlen, so wie im Fall von Afghanistan. Der einfachste Weg, das zu beheben, ist, die betreffenden Datenzeilen zu löschen. Für Afghanistan klicken wir den Zeilenkopf (2) mit der linken Maustaste an und wählen Zeilen löschen:
So können verfahren wir mit allen Einträgen, die nicht in unsere Untersuchung passen:
Länder mit fehlenden Daten
Einträge für Kontinente wie Africa
Stadtstaaten, in denen eine einzige Großveranstaltung als Superspreader-Event ausreicht, die Statistik zu verzerren
Um ein kleines, überschaubares Beispiel zu erhalten, erstellen wir nur ein Diagramm für alle Staaten, deren Name mit A und B anfängt. Nach der o.a. Datenbereinigung klicken wir das Feld B1 (in dem people_fully_vaccinated_per_hundred steht) an und ziehen die Maustaste bis auf Spalte reproduction_rate und Zeile Burundi:
Dann wählen wir aus dem Hauptmenü Einfügen – Diagramm.
Im Diagramm-Assistent, der sich nun öffnet, wählen wir XY (Streudiagramm) und sehen eine Vorschau:
Ein Klick auf Weiter führt uns zum nächsten Schritt, in dem die Einstellungen automatisch korrekt sein sollten:
Datenreihen in Spalten
Erste Zeile als Beschriftung
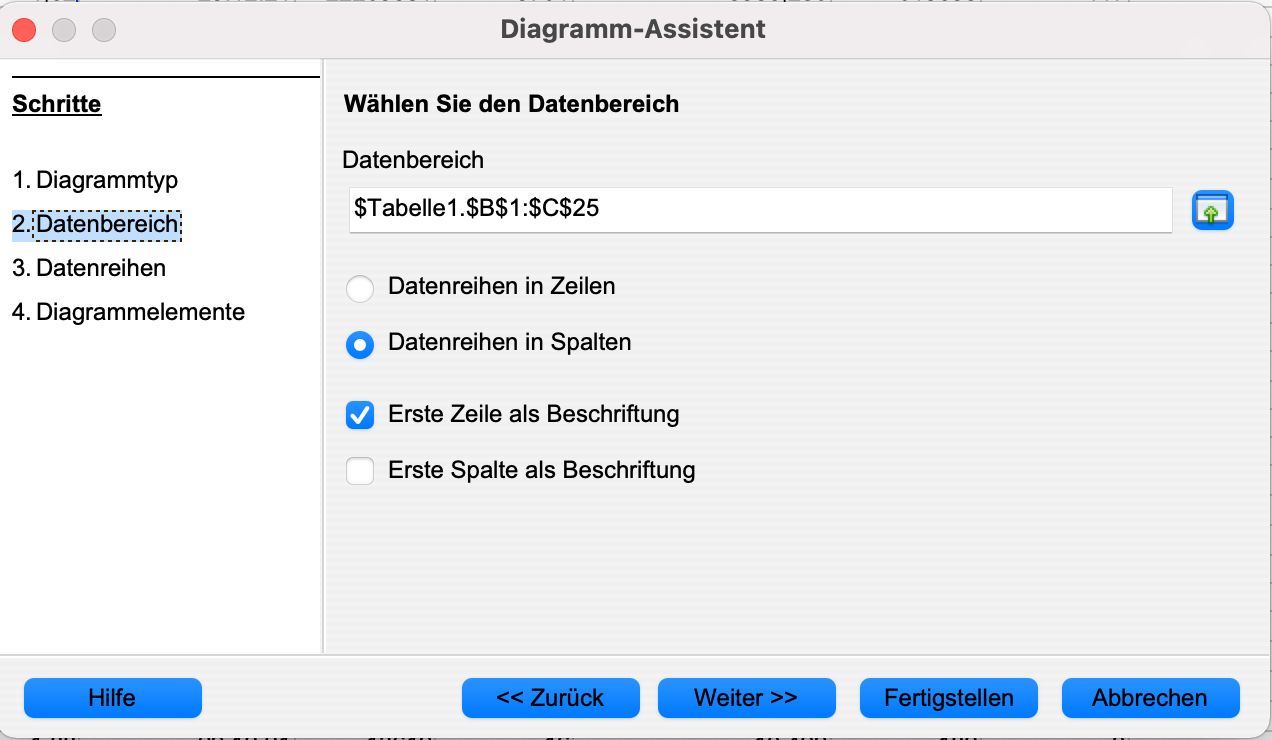
Ein Klick auf Weiter führt uns zur Definition der Datenreihen, in der die Voreinstellungen passen sollten und wir Beschriftungen für die Datenpunkte hinzufügen können. Dazu klicken wir den Knopf rechts neben dem Textfeld, das sich unter Datenbeschriftung befindet, an.
Daraufhin erscheint ein kleines Fenster, in dem wir die Datenbereich eingeben könnten, aber einfacher ist es, mit der Maus auf das Feld Albania zu klicken und die Maus bis auf das Feld Burundi zu ziehen.
Es erscheint wieder der vorherige Dialog, in dem wir durch Anklicken von ‘Weiter’ zum letzten Teilschritt kommen und Beschriftungen eingeben:
Titel: ‘Reproduktionsrate in den Ländern A-B’
X-Achse: Impfquote
Y-Achse: Reproduktionsrate
Wählen Sie das Häkchen Legende anzeigen ab. Optional können Sie wählen: Gitter anzeigen – X-Achse.
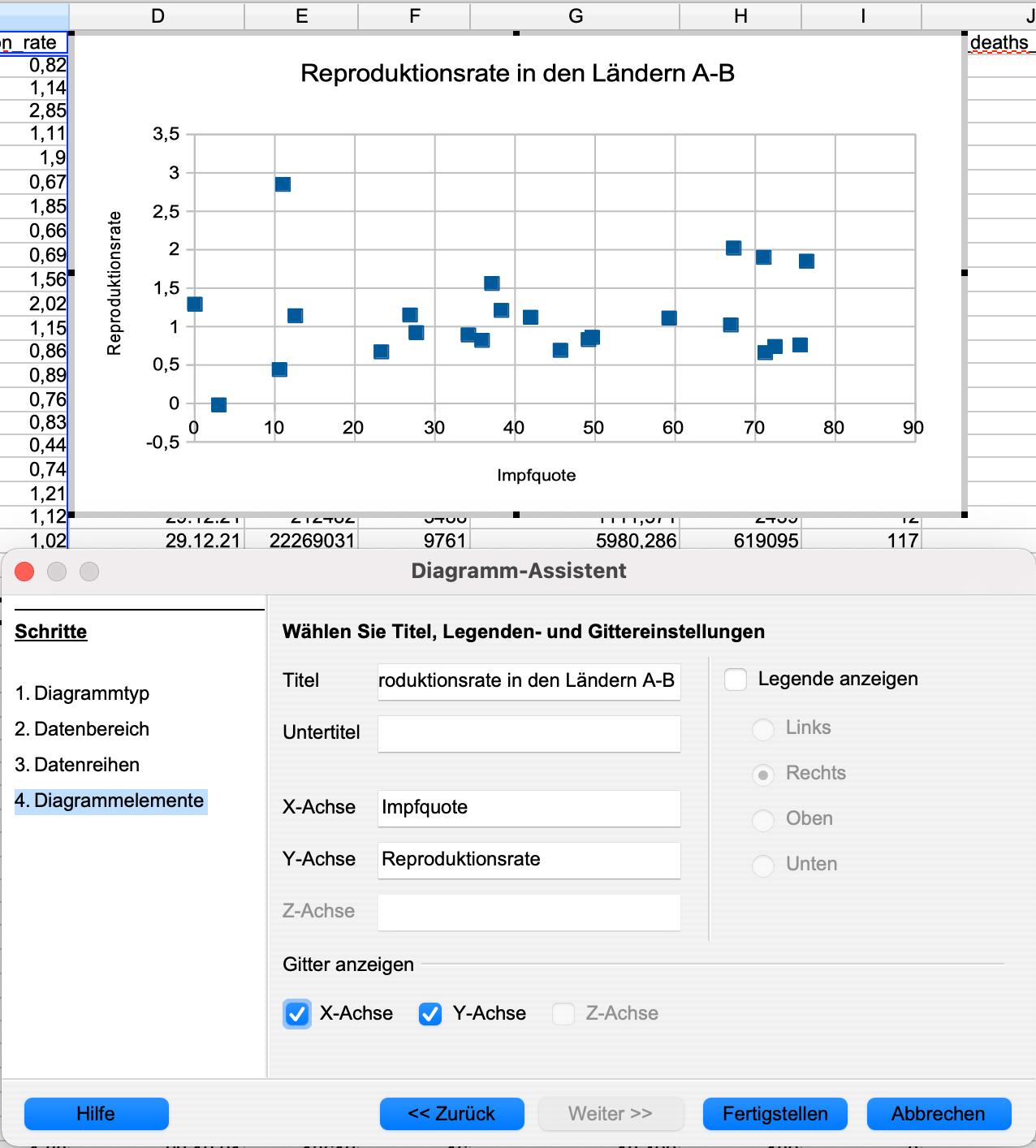
Mit einem Klick auf Fertigstellen ist das Grunddiagramm fertig und kann größer gezogen werden.
Beschriftungen
Mit Einfügen – Datenbeschriftungen… können die Länder nun im Diagramm kenntlich gemacht werden:
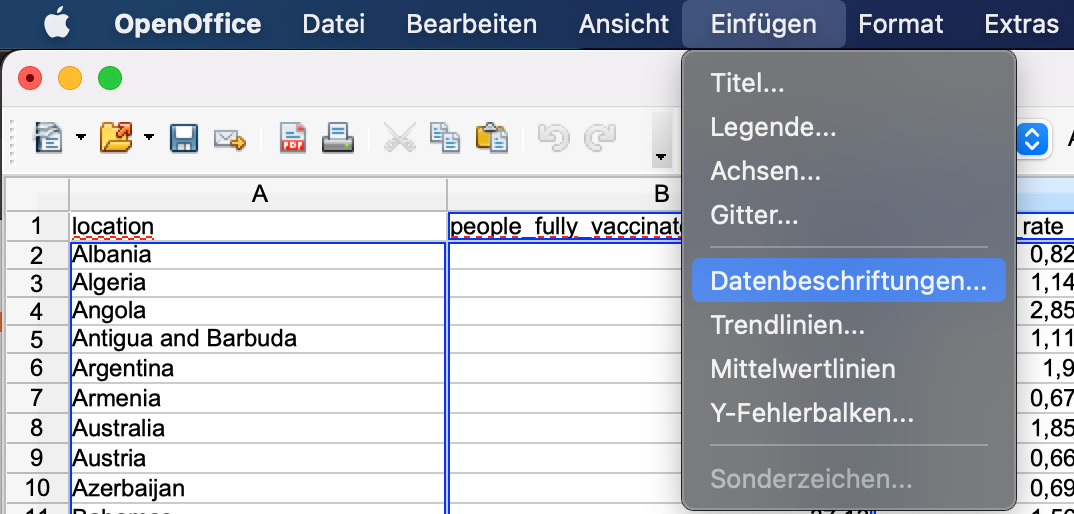
Sollte der Dialog anders aussehen, hilft es, zuerst einmal per rechtem Mausklick auf das Diagramm Bearbeiten zu wählen. Im nun erscheinenden Dialog muss Kategorie anzeigen gewählt werden,
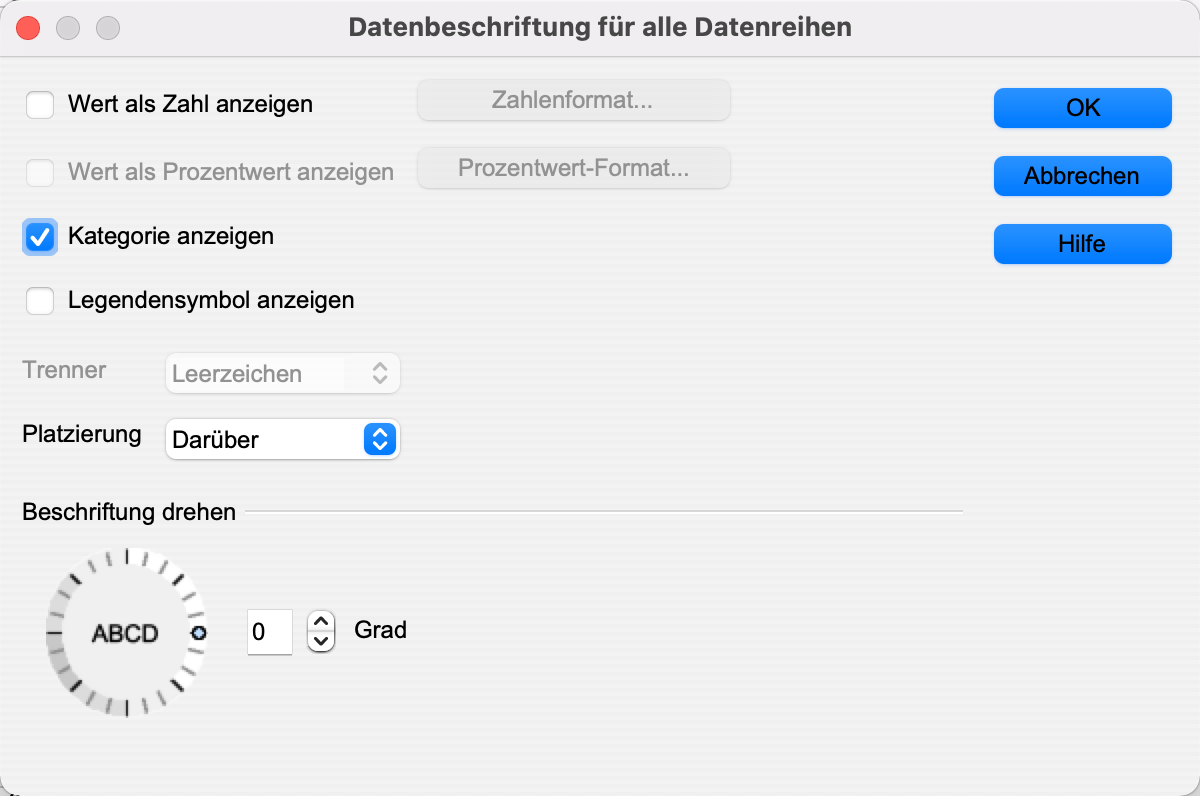
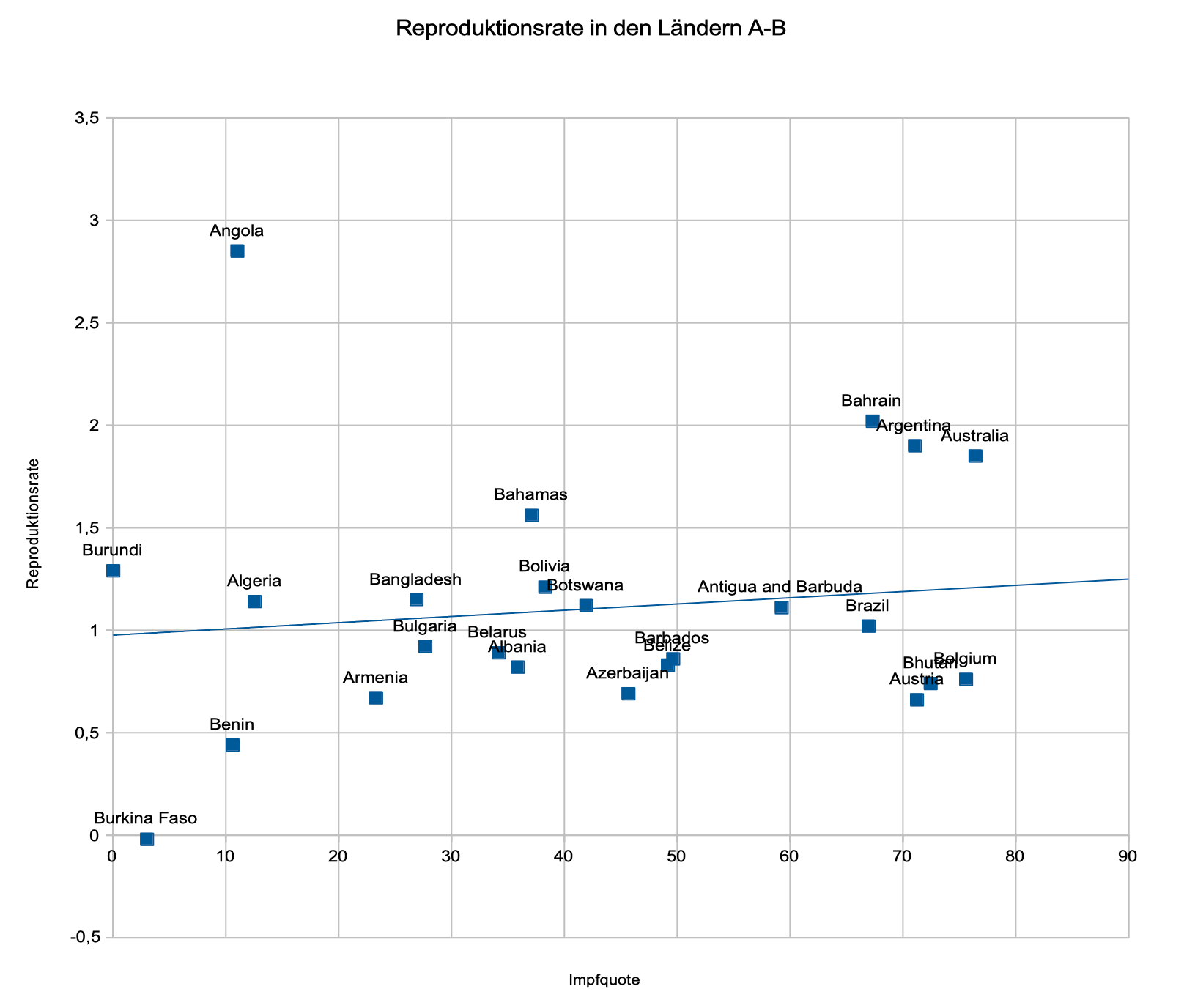
und ein Klick auf OK erzeugt folgendes Diagramm:

Weitergehende Möglichkeiten
Regression
Im Hauptmenü kann man per Einfügen – Trendlinien eine Regression berechnen und einzeichnen lassen.
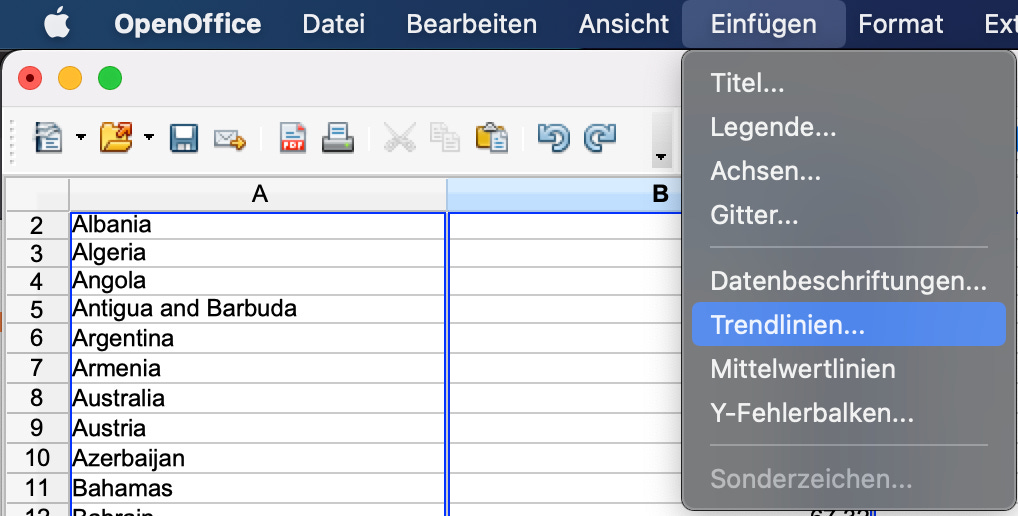
Das typische Mittel ist die lineare Regression.
Das Ergebnis ist eine Trendlinie, die alle Daten mit einbezieht und eine spezielle Art von Mittelung bildet. Diese ist nur sinnvoll anwendbar, wenn es einen Kausalzusammenhang zwischen den betrachteten Größen gibt. Ist ein Zusammenhang nicht nachgewiesen, ist eine Regressionskurve erst einmal nur ein Indiz für einen Zusammenhang, das umso stärker ist, je näher die Messpunkte an der Ergebnislinie liegen.
Datensatzauswahl
Die Wahl der Datensätze (in diesem Fall der Länder) sollte einigermaßen homogen sein, um nicht Äpfel mit Birnen zu vergleichen, aber auch nicht zu klein, damit statistische Ausreißer (die es immer gibt) nicht das Gesamtbild verzerren.
Wahl der Messzahlen
Essentiell ist es, als Messwerte relative Zahlen zu verwenden, in unserem Beispiel Prozentzahlen oder Fälle pro Million Einwohner (per_million im Spaltennamen). Ein Vergleich von absoluten Infektionszahlen zwischen Island und China ist sinnlos: 5.000 Fälle in Island betreffen mehrere Prozent der Bevölkerung, für China ist die Zahl winzig.
In der Datei gibt es geglättete Werte (smoothed im Spaltennamen), diese Werte sind über sieben Tage gemittelt und gleichen zufällige Tagesereignisse (wie Wochenenden) aus, sie sind gegenüber den einfachen Daten (Momentaufnahmen für einen Tag) vorzuziehen.